引言
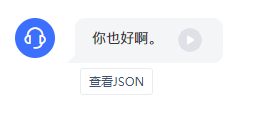
在与实现了语音合成、语义分析、机器翻译等算法的后端交互时,页面可以设计成更为人性化、亲切的方式。我们采用类似于聊天对话的实现,效果如下:
-
智能客服(输入文本,返回引擎处理后的文本结果)
-
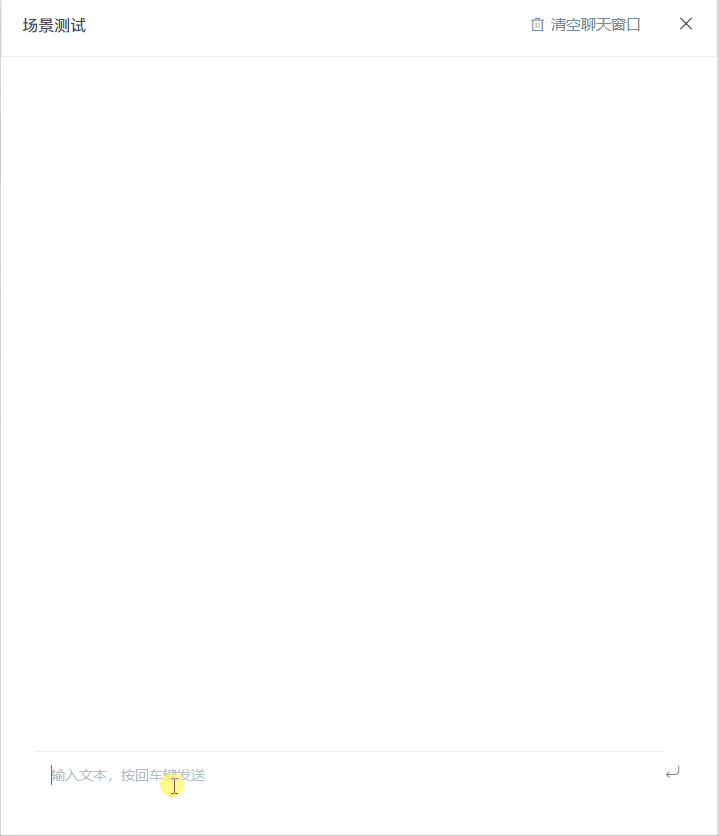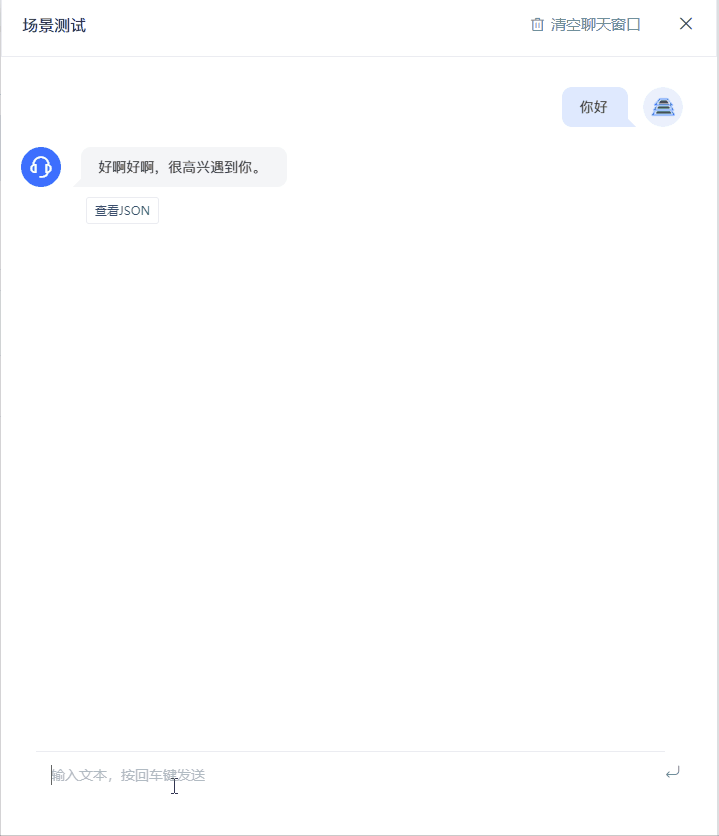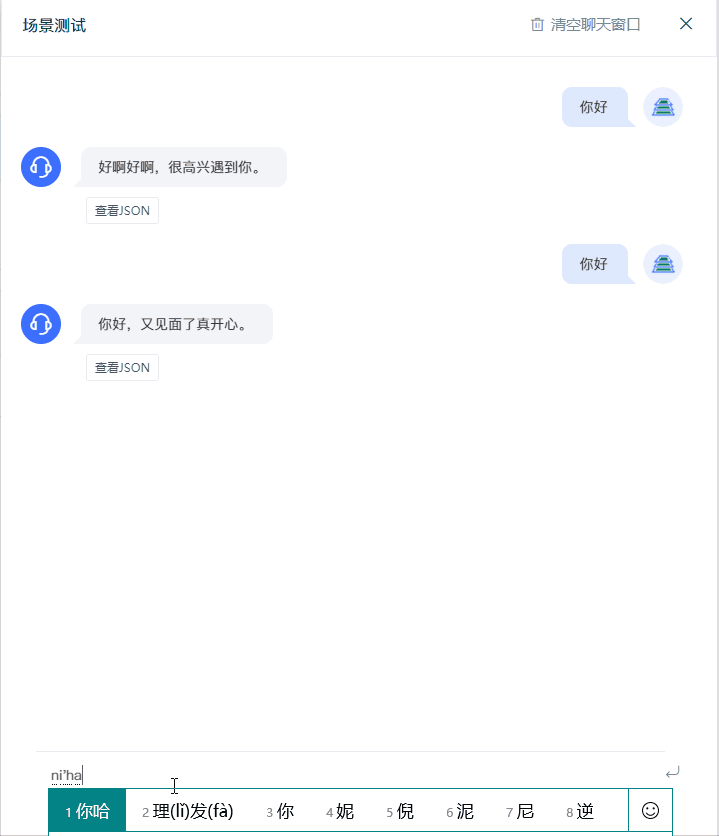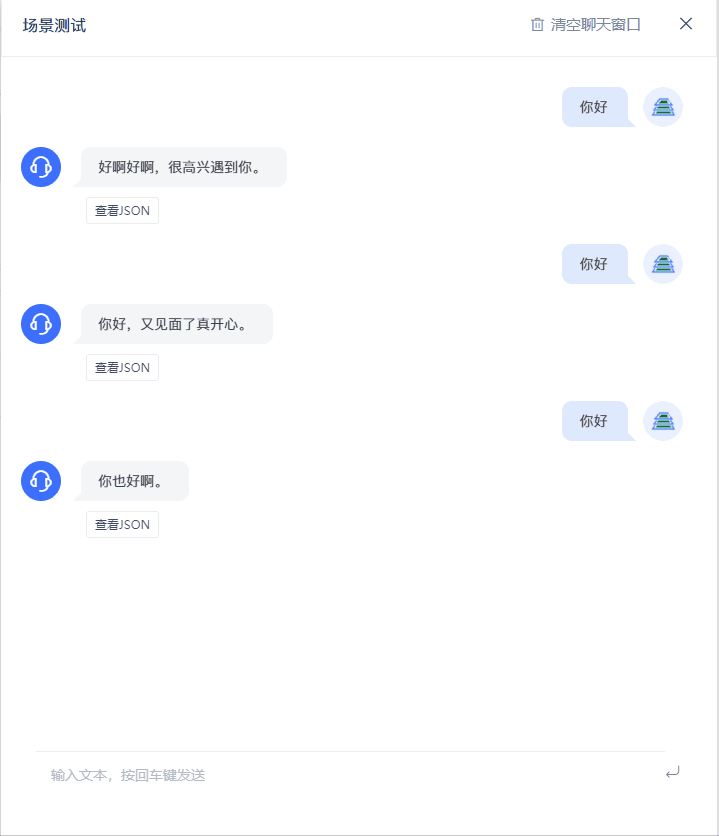
语音合成(输入文本,返回文本以及合成的音频)

如上图所示,返回文本后,再返回合成出的音频。
音频按钮嵌在对话气泡中,可以点击播放。
- 语音识别(在页面录制语音发送,页面实时展示识别出的文本结果)
实现功能及技术要点
1、基于WebSocket实现对话流
页面与后端的交互是实时互动的,所以采用WebSocket协议,而不是HTTP请求,这样后端推送回的消息可以实时显示在页面上。
WebSocket的返回是队列的、无序的,在后续处理中我们也需要注意这一点,在后文中会说到。
2、调用设备麦克风进行音频录制和转码加头,基于WebAudio、WaveSurferJS等实现音频处理和绘制
3、基于Vue的响应式页面实现
4、CSS3 + Canvas + JS 交互效果优化
- 录制音频CSS动画效果
- 聊天记录自动滚动
下面给出部分实现代码。
集成WebSocket
我们的聊天组件是页面侧边打开的抽屉(el-drawer),Vue组件会在打开时创建,关闭时销毁。在组件中引入WebSocket,并管理它的开、关、消息接收和发送,使它的生命周期与组件一致(打开窗口时创建ws连接,关闭窗口时关闭连接,避免与后台连接过多。)
created(){
if (typeof WebSocket === 'undefined') {
alert('您的浏览器不支持socket')
} else {
// 实例化socket
this.socket = new WebSocket(this.socketServerPath)
// 监听socket连接
this.socket.onopen = this.open
// 监听socket错误信息
this.socket.onerror = this.error
// 监听socket消息
this.socket.onmessage = this.onMessage
this.socket.onclose = this.close
}
}
destroyed(){
this.socket.close()
}
如上,将WebSocket的事件绑定到JS方法中,可以在对应方法中实现对数据的接收和发送。
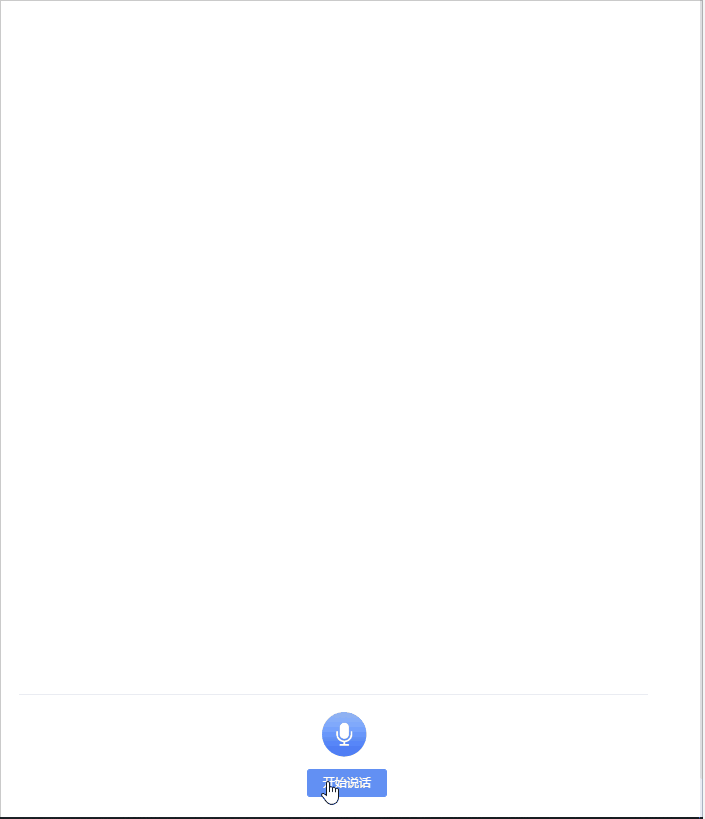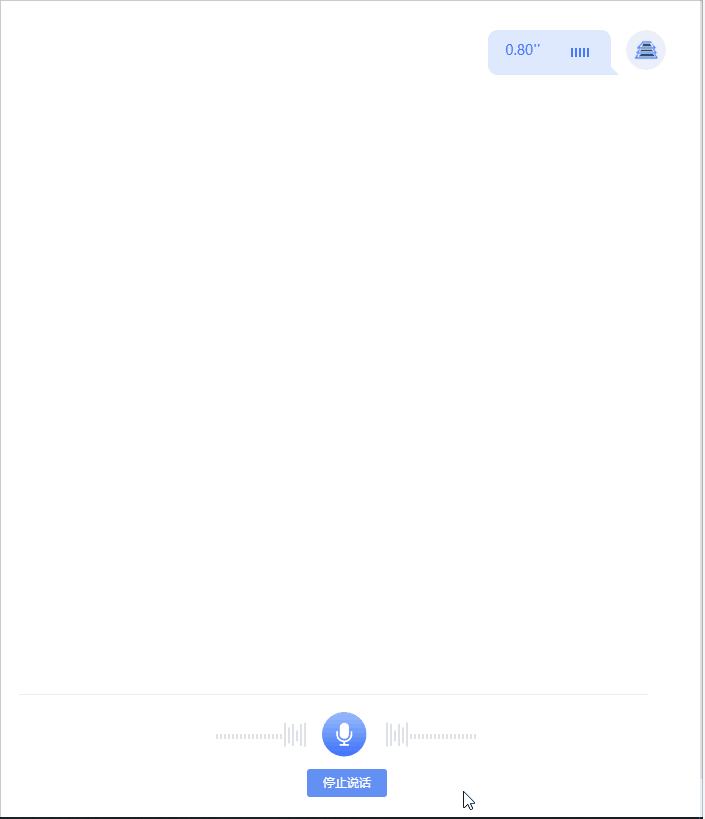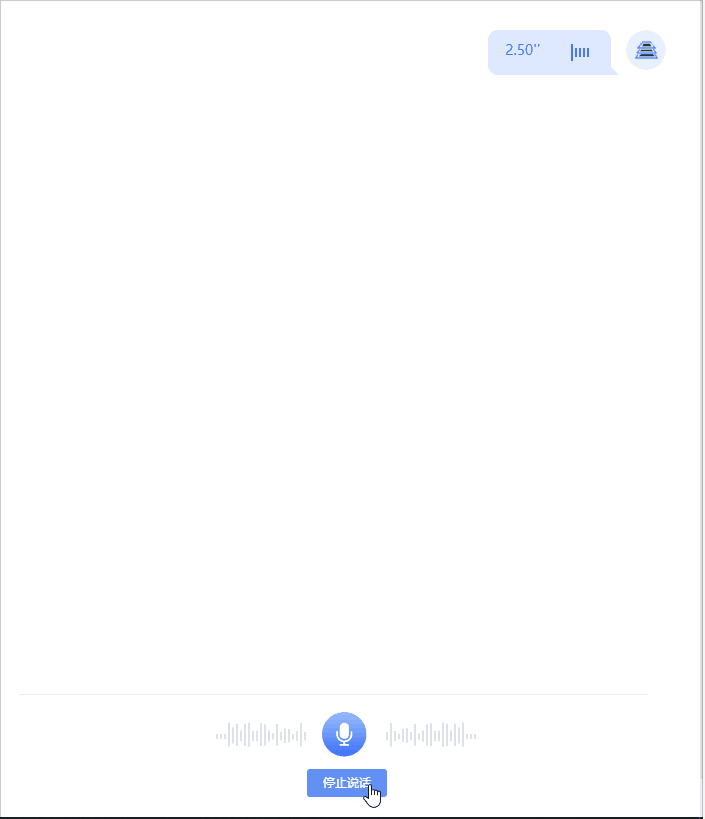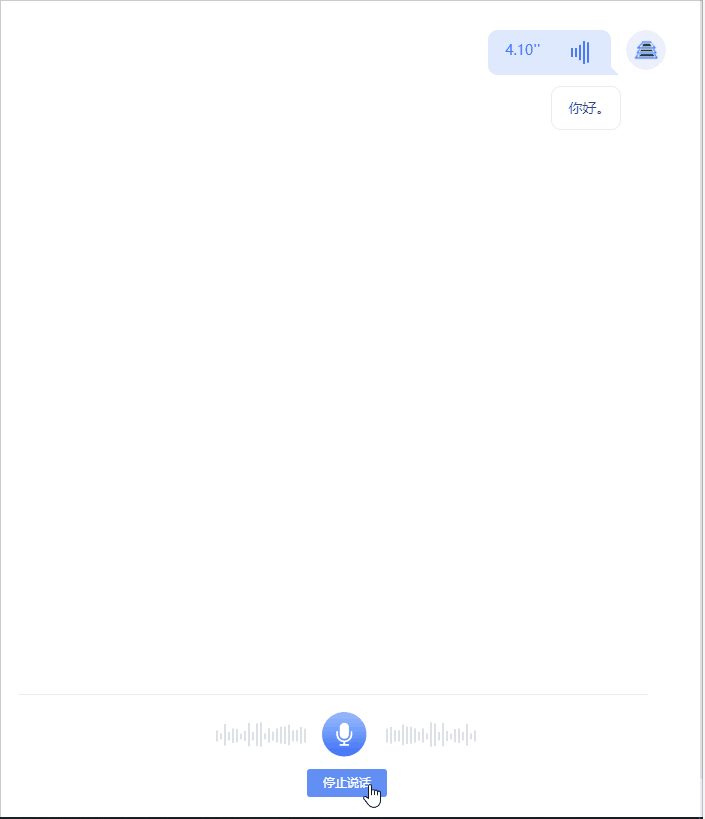
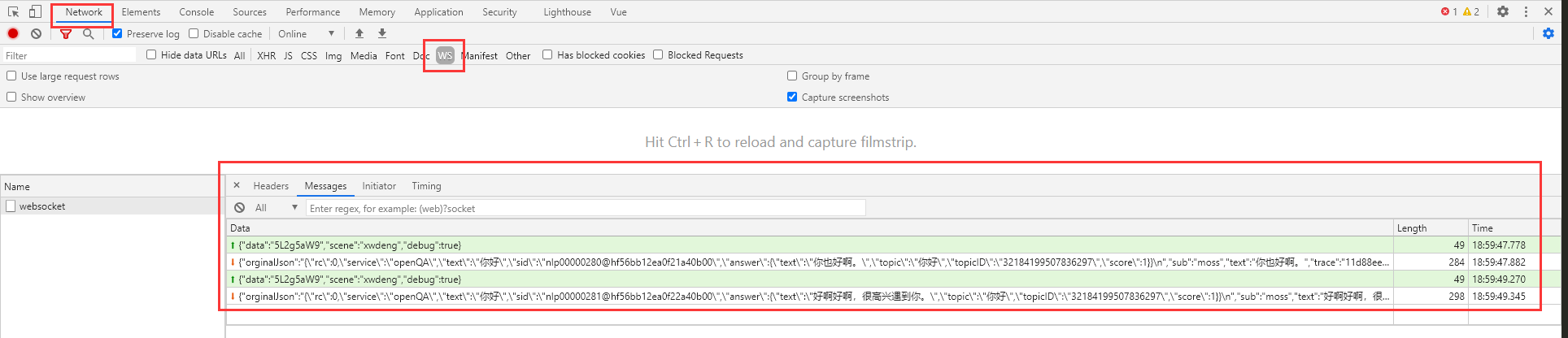
打开浏览器控制台,选中指定的标签,便于对WebSocket连接进行监控和查看。
音频录制采集
从浏览器端音频和视频采集基于网页即时通信(Web Real-Time
Communication,简称WebRTC) 的API。通过WebRTC的getUserMedia实现,获取一个MediaStream对象,将该对象关联到AudioContext即可获得音频。
可参考RecorderJS的实现:
https://github.com/mattdiamond/Recorderjs/blob/master/examples/example_simple_exportwav.html
if (navigator.getUserMedia) {
navigator.getUserMedia(
{ audio: true }, // 只启用音频
function(stream) {
var context = new(window.webkitAudioContext || window.AudioContext)()
var audioInput = context.createMediaStreamSource(stream)
var recorder = new Recorder(audioInput)
},
function(error) {
switch (error.code || error.name) {
case 'PERMISSION_DENIED':
case 'PermissionDeniedError':
throwError('用户拒绝提供信息。')
break
case 'NOT_SUPPORTED_ERROR':
case 'NotSupportedError':
throwError('浏览器不支持硬件设备。')
break
case 'MANDATORY_UNSATISFIED_ERROR':
case 'MandatoryUnsatisfiedError':
throwError('无法发现指定的硬件设备。')
break
default:
throwError('无法打开麦克风。异常信息:' + (error.code || error.name))
break
}
}
)
} else {
throwError('当前浏览器不支持录音功能。')
}
注意: 若navigator.getUserMedia获取到的是undefined,是Chrome浏览器的安全策略导致的,需要通过https请求或配置浏览器,配置地址: chrome://flags/#unsafely-treat-insecure-origin-as-secure
浏览器采集到的音频为PCM格式(PCM (脉冲编码调制 Pulse Code Modulation)),需要对音频加头才能在页面上进行播放。注意加头时采样率、采样频率、声道数量等必须与采样时相同,不然加完头后的音频无法解码。参考查看https://github.com/mattdiamond/Recorderjs/blob/master/src/recorder.js中exportWav方法。
业务中对接的语音识别引擎为实时转写引擎,即:不是录制完成后再发送,而是一边录制一边进行编码并发送。
使用onaudioprocess方法监听语音的输入:
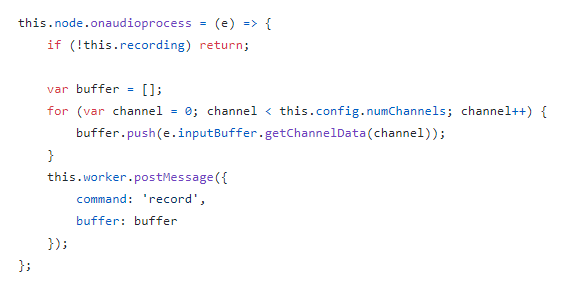
参考这个实现,我们可以在每次监听到有数据写入时,从buffer中获取到录制到的数据,并进行编码、压缩,再通过WebSocket发送。
Vue组件设计和业务实现
分析页面业务逻辑,将代码拆分成两个组件:
ChatDialog.vue 聊天对话框页面,根据输入类型,分为文本输入、语音输入。
ChatRecord.vue聊天记录组件,根据发送方(自己或者系统)展示向左/向右的气泡,根据内容显示文本、音频等。ChatDialog是ChatRecord的父组件,遍历ChatDialog中的chatList对象(Array),将chatList中的项注入到ChatRecord中。
<div class="chat-list">
<div v-for="(item,index) in chatList" :key="index" class="msg-wrapper">
<chat-record ref="chatRecord" :data="item" @showJson="showJsonDialog"></chat-record>
</div>
<div id="msg_end" style="height:0px; overflow:hidden"></div>
</div>
</div>
对于聊天记录的气泡展示,与数据类型相关性很强,ChatRecord组件只关心对数据的处理和展示,我们可以完全不用关心消息的发送、接收、音频的录制、停止录制、接受音频等逻辑,只需要根据数据来展示不同的样式即可。
这样Vue的响应式就充分获得了用武之地:无需用代码对样式展示进行控制,只需要设计合理的数据格式和样式模板,然后注入不同的数据即可。
模板页面: 使用v-if控制,修改chatList里的对象内容即可改变页面展示。
根据业务需求,将ChatRecord可能接收到的数据分为以下几类:
发送方为自己:
- 文本输入,显示文本
实现简单,不做赘述。
- 语音输入 Loading状态,显示波纹动画和计时

计时器使用JS的setInterval方法,每100ms更新一次录制时长
this.recordTimer = setInterval(() => {
this.audioDuration = this.audioDuration + 0.1
}, 100)
停止后清空计时器:
clearInterval(this.recordTimer)
- 语音输入完毕,根据录制的语音,绘制波纹
效果:
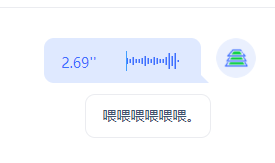
使用wavesurfer插件:
initWaveSurfer() {
this.$nextTick(() => {
this.wavesurfer = WaveSurfer.create({
container: this.$refs.waveform,
height: 20,
waveColor: '#3d6fff',
progressColor: 'blue',
backend: 'MediaElement',
mediaControls: false,
audioRate: '1',
fillParent: false,
maxCanvasWidth: 500,
barWidth: 1,
barGap: 2,
barHeight: 5,
barMinHeight: 3,
normalize: true,
cursorColor: '#409EFF'
})
this.convertAudioToUrl(this.waveAudio).then((res) => {
this.wavesurfer.load(res)
setTimeout(() => {
this.audioDuration = this.getAudioDuration()
}, 100)
})
})
},
// 将音频转化成url地址
convertAudioToUrl(audio) {
let blobUrl = ''
if (this.data.sendBy === 'self') {
blobUrl = window.URL.createObjectURL(audio)
return new Promise((resolve) => {
resolve(blobUrl)
})
} else {
return this.base64ToBlob({
b64data: audio,
contentType: 'audio/wav'
})
}
},
base64ToBlob({ b64data = '', contentType = '', sliceSize = 512 } = {}) {
return new Promise((resolve, reject) => {
// 使用 atob() 方法将数据解码
let byteCharacters = atob(b64data)
let byteArrays = []
for (
let offset = 0;
offset < byteCharacters.length;
offset += sliceSize
) {
let slice = byteCharacters.slice(offset, offset + sliceSize)
let byteNumbers = []
for (let i = 0; i < slice.length; i++) {
byteNumbers.push(slice.charCodeAt(i))
}
// 8 位无符号整数值的类型化数组。内容将初始化为 0。
// 如果无法分配请求数目的字节,则将引发异常。
byteArrays.push(new Uint8Array(byteNumbers))
}
let result = new Blob(byteArrays, {
type: contentType
})
result = Object.assign(result, {
// 这里一定要处理一下 URL.createObjectURL
preview: URL.createObjectURL(result),
name: `XXX.wav`
})
resolve(window.URL.createObjectURL(result))
})
},
发送方为系统:
页面嵌入audio标签,将hidden设置为true使其不显示:
<div class="audio-player">
<svg-icon v-if="!isPlaying" icon-class='play' @click="onClickAudioPlayer" />
<svg-icon v-else icon-class='pause' @click="onClickAudioPlayer" />
<audio :src="playAudioUrl" autostart="true" hidden="true" ref="audioPlayer" />
</div>
playAudioUrl的生成参考上面生成的wavesurfer的url。
使用isPlaying参数记录当前音频的播放状态,并使用setTimeout方法,当播放了音频时长后,将播放按钮自动置为play。
onClickAudioPlayer() {
if (this.isPlaying) {
this.$refs.audioPlayer.pause()
this.isPlaying = false
} else {
// 每次点击时,开始播放,并在播放完毕将isPlaying置为false
this.$refs.audioPlayer.currentTime = 0
this.$refs.audioPlayer.play()
this.isPlaying = true
setTimeout(() => {
// 将正在播放重置为false
this.isPlaying = false
}, Math.ceil(this.$refs.audioPlayer.duration) * 1000)
}
},
- 聊天记录自动定位到最后一条:
使用
scrollIntoView()方法
- 记录每次会话对应的记录ID(
recordId):
定义单次会话的id,并在返回的消息中回传,从而建立多条websocket返回的关联关系。
以上就是全部实现。难点主要是请求麦克风权限和对音频进行编码,在加wav头时必须保证和采样时的采样率、频率一致 。
%20--%3E%0A%3Csvg%20width%3D%22400%22%20height%3D%22362.25%22%20version%3D%221.1%22%20viewBox%3D%220%200%20105.83%2095.845%22%20xml%3Aspace%3D%22preserve%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%3E%3Cg%20transform%3D%22matrix(.713%200%200%20.713%2077.075%2071.416)%22%20fill%3D%22none%22%20stroke%3D%22%2320b2aa%22%3E%3Cg%20transform%3D%22matrix(1.7758%200%200%201.7758%20-218.04%20-53.747)%22%3E%3Cg%20transform%3D%22matrix(1.0075%200%200%201.0075%20-117.66%20-102.15)%22%20fill%3D%22none%22%20stroke%3D%22%23008000%22%3E%3Cg%20transform%3D%22translate(6.3294%2021.625)%22%3E%3Cg%20transform%3D%22translate(2.2098%2031.932)%22%3E%3Cg%20transform%3D%22translate(143.47%20-53.536)%22%20stroke%3D%22%2320e0cd%22%3E%3Cpath%20transform%3D%22translate(-2.2098%20-31.932)%22%20d%3D%22m81.211%20180.38%2019.707%200.26372%22%20stroke-width%3D%223.683%22%2F%3E%3Cg%20transform%3D%22translate(-.36252)%22%3E%3Cpath%20d%3D%22m89.544%20146.87v-6.794%22%20stroke-width%3D%222.6458%22%2F%3E%3Cpath%20d%3D%22m88.77%20141.34%206.6272-8.1886%22%20stroke-width%3D%222.3347%22%2F%3E%3Cpath%20d%3D%22m89.919%20141.46-5.5766-5.8386%22%20stroke-width%3D%222.3102%22%2F%3E%3C%2Fg%3E%3Ccircle%20cx%3D%22100.95%22%20cy%3D%22126.47%22%20r%3D%226.9136%22%20stroke-width%3D%222.6458%22%2F%3E%3Ccircle%20cx%3D%2279.351%22%20cy%3D%22130.4%22%20r%3D%225.0854%22%20stroke-width%3D%222.6458%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22matrix(1.4025%200%200%201.4025%2078.297%20-26.312)%22%20fill%3D%22none%22%20stroke%3D%22%232e8b57%22%3E%3Ccircle%20cx%3D%2234.846%22%20cy%3D%2231.29%22%20r%3D%223.9152%22%20stroke-width%3D%221.8521%22%2F%3E%3Ccircle%20cx%3D%224.8413%22%20cy%3D%2231.29%22%20r%3D%223.9152%22%20stroke-width%3D%221.8521%22%2F%3E%3Cpath%20d%3D%22m9.2604%2052.775h21.167%22%20stroke-width%3D%222.6458%22%2F%3E%3Cpath%20d%3D%22m19.844%2053.834v-37.849%22%20stroke-width%3D%222.5838%22%2F%3E%3Cg%20stroke-width%3D%222.6458%22%3E%3Ccircle%20cx%3D%2219.844%22%20cy%3D%227.1851%22%20r%3D%225.739%22%2F%3E%3Cpath%20d%3D%22m6.6146%2037.959%205.2917%205.2917h7.9375%22%2F%3E%3Cpath%20d%3D%22m33.073%2037.959-5.2917%205.2917h-7.9375%22%2F%3E%3C%2Fg%3E%3Ccircle%20cx%3D%2231.804%22%20cy%3D%2217.056%22%20r%3D%223.9152%22%20stroke-width%3D%221.3229%22%2F%3E%3Ccircle%20cx%3D%227.884%22%20cy%3D%2217.056%22%20r%3D%223.9152%22%20stroke-width%3D%221.3229%22%2F%3E%3Cpath%20d%3D%22m9.2604%2023.406%2010.583%202.6458%2010.583-2.6458%22%20stroke-width%3D%222.6458%22%2F%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(61.911%20-10.894)%22%3E%3Cpath%20d%3D%22m8.1887%2058.6h23.31%22%20stroke-width%3D%223.7108%22%2F%3E%3Cg%20transform%3D%22translate(0%203.7438)%22%3E%3Ccircle%20cx%3D%2233.971%22%20cy%3D%2233.263%22%20r%3D%224.79%22%20stroke%3D%22%2320b2aa%22%20stroke-width%3D%221.8527%22%2F%3E%3Ccircle%20cx%3D%225.716%22%20cy%3D%2233.263%22%20r%3D%224.79%22%20stroke-width%3D%221.8521%22%2F%3E%3Cg%20stroke-width%3D%222.6458%22%3E%3Cpath%20d%3D%22m19.844%2053.743v-25.896%22%2F%3E%3Ccircle%20cx%3D%2219.844%22%20cy%3D%2218.683%22%20r%3D%227.0212%22%2F%3E%3Cpath%20d%3D%22m6.8958%2040.795%2012.948%203.237%2012.948-3.237%22%2F%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E%0A)